ICASSP 2022 · Google Research
Improving Bird Classification with Unsupervised Sound Separation
Presented by
Amitesh Badkul

Photo: Amitesh Badkul.
Birding apps can turn a walk into a species list in seconds.
Bird presence and absence reveal habitat quality, biodiversity, and ecosystem stress.
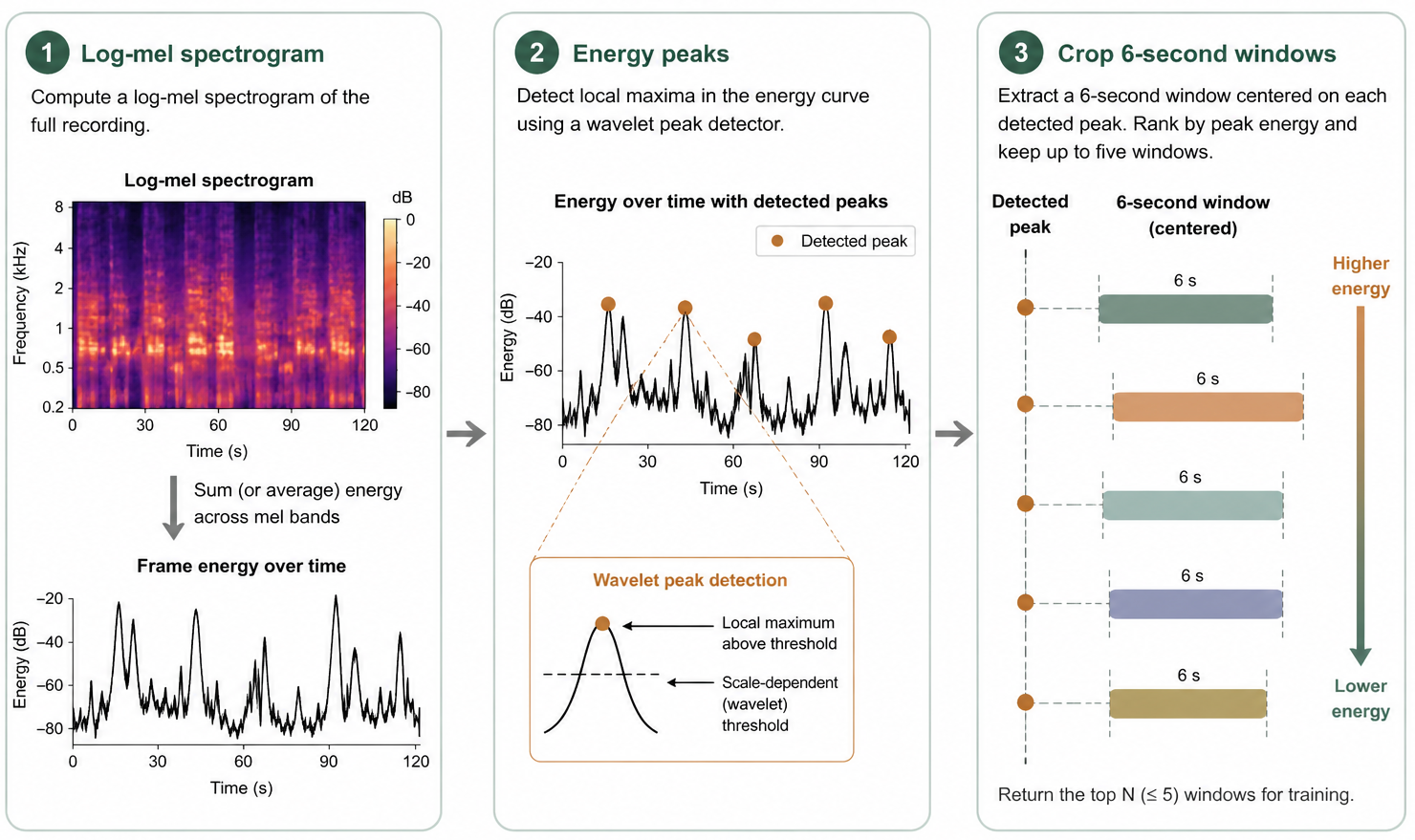
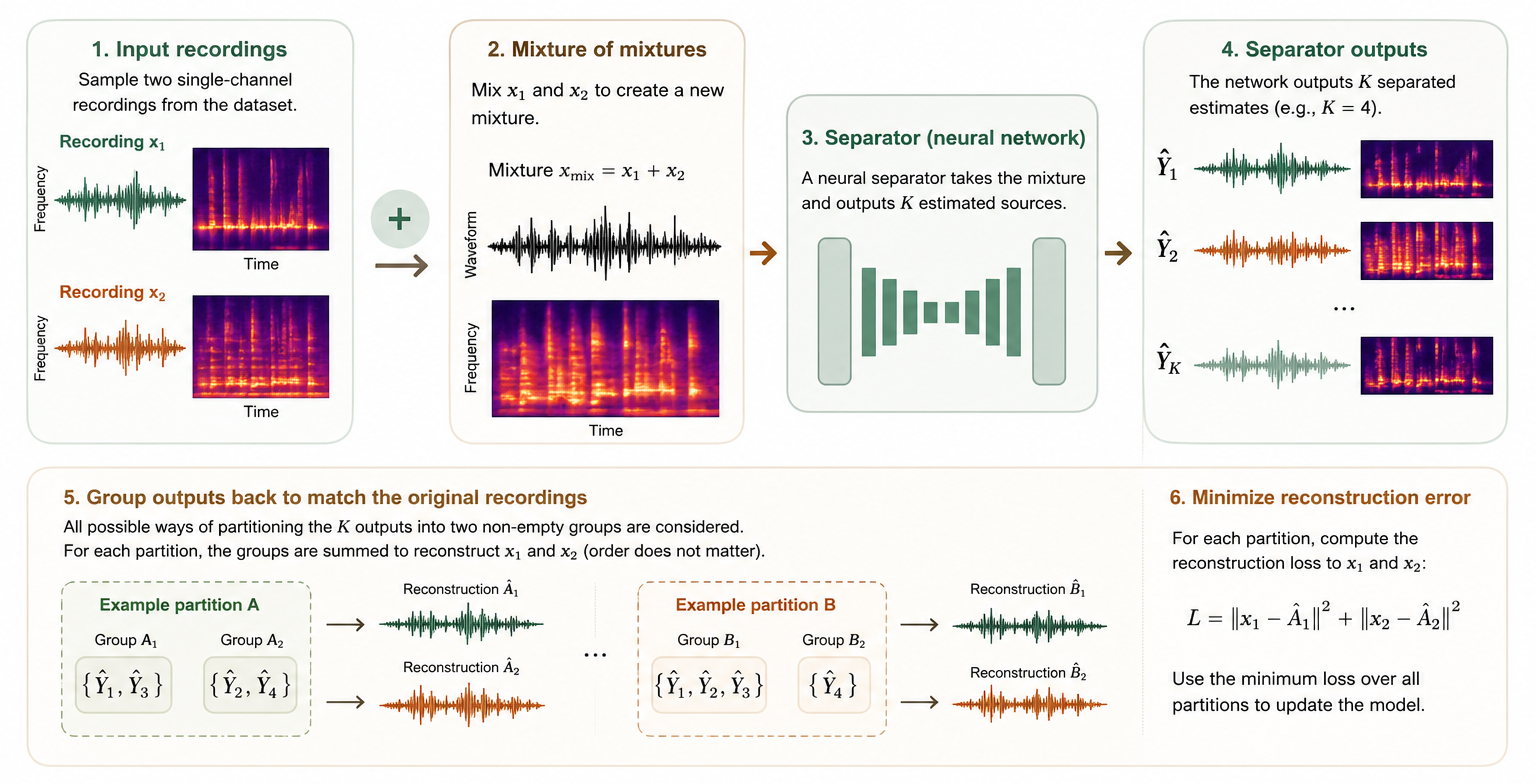
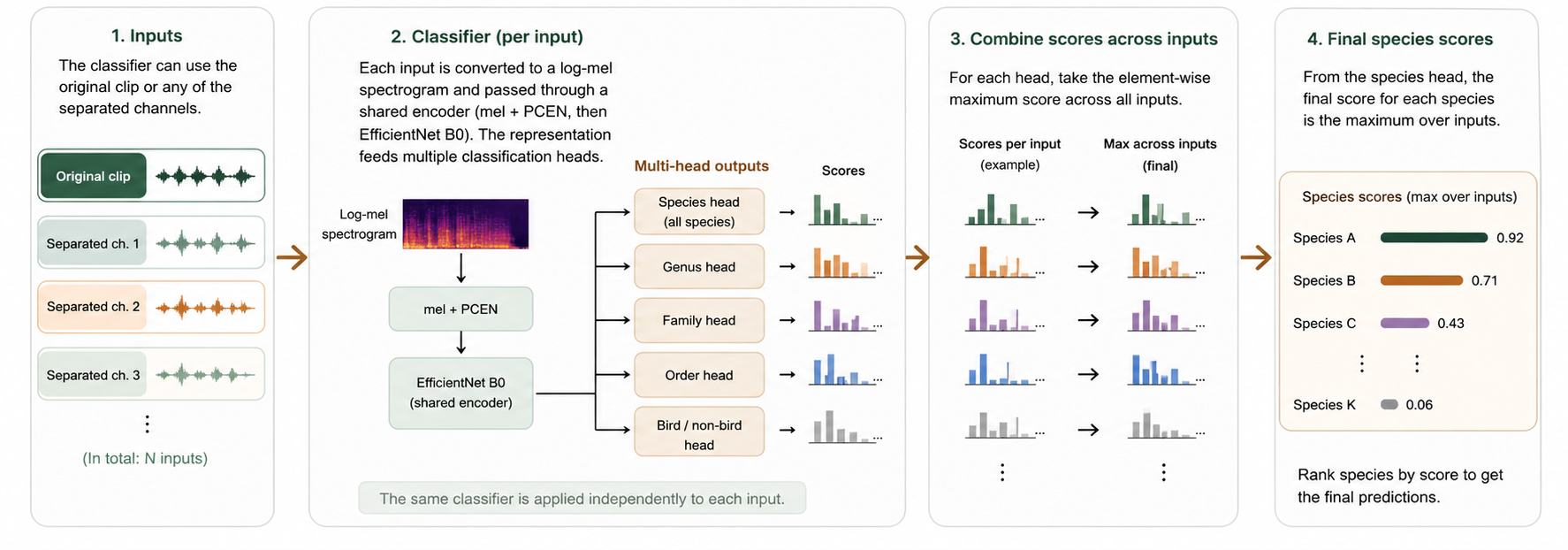
Real recordings contain overlap, wind, insects, and weak labels, so ordinary models miss faint birds.